This blog post will be going through the nature of datafication of many elements in the modern world, and applying a principal of machine learning to describe the problems through the analogy of a system that processes data.
Datafication is the process of converting elements of our lives into discrete and quantifiable instances. Examples of this could be something simple, such as what you purchased last time you went grocery shopping. Every item on a receipt, each with its associated product ID and price, arranged in a neat row matrix. As the influence of technology, particularly the so called ‘big data’, has increased, many more things have been tracked and converted to convenient lists of values.
The primary objective of datafication is, of course, profit. By determining what items you are more likely to buy, and when you are more likely to buy them, an advertiser can subtly place the right product in the right place at the right time. The same principle holds for other areas than advertising, such as land development, where the value of establishing housing in different areas can be assessed based on the values of nearby construction, or grocery store inventory software, which can track the number of products coming into and going out of a store, and automatically order common items.
Datafication is actually beneficial in many areas. Patterns which might not be immediately apparent at a glance can appear with a large dataset, and finding patterns is not inherently bad. Medical diagnoses, for example, can be benefited by the introduction of data agglomeration systems, such as for patient pre-screening, for example in an ICU.
The problems with datafication arise from two main areas: misuse and overfitting. Misuse of data, such as to track and manipulate people, is regrettably commonplace in the modern world. Technology is, after all, controlled by the people who own it, and you don’t generally get rich by taking the kindest and most ethical path available to you. Overfitting is another area where datafication can be dangerous, though.
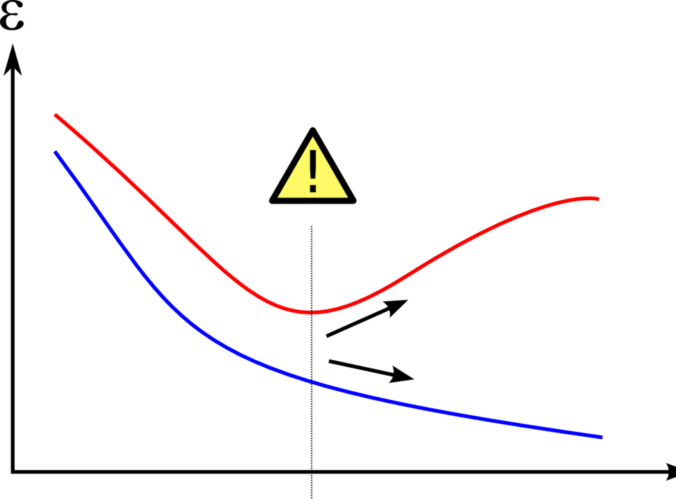
Overfitting is a principle of machine learning which goes occurs when a machine becomes too good at following the data that it is using. Ordinarily, getting better at something is considered to be a good thing, but overfitting occurs when a machine learns to replicate patterns which are present in the training data which don’t exist outside of the training data. For example, if you were to track every car accident which took place across the globe, the colors of the cars would probably just correlate with the most common car colors across the globe, but if you were to take only a few crashes, then there is a high chance that the colors of the cars would not correlate with the most common colors of cars on the road, which may erroneously lead to the conclusion that car color is strongly correlated with car crashes.
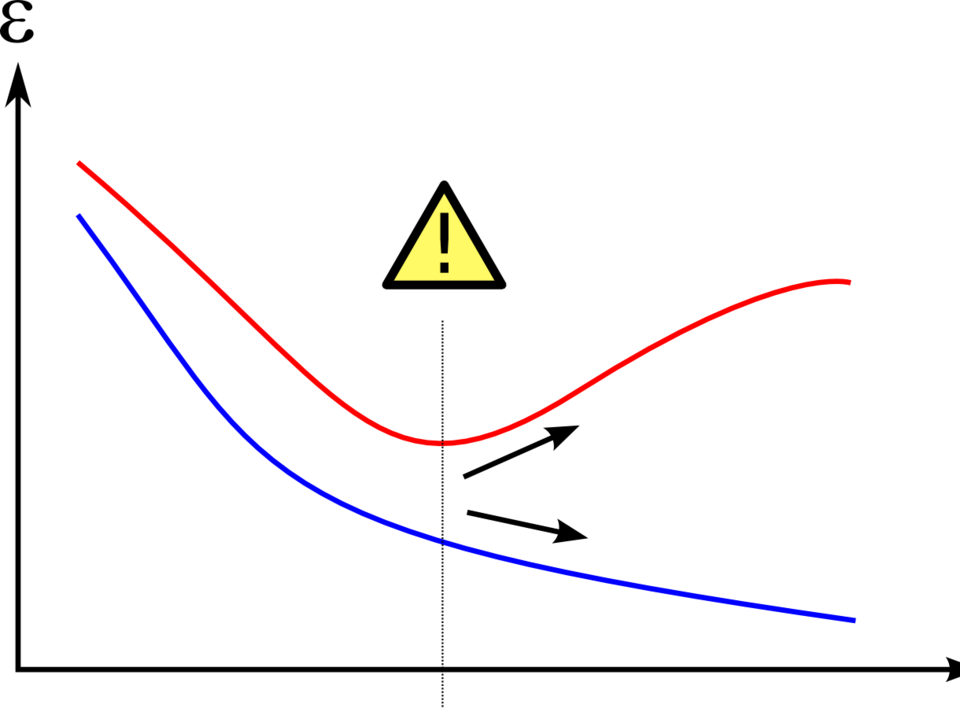
Image credit to Dake~commonswiki, sourced under creative commons share-alike 3.0. No edits made
The same type of thing can happen in datafied systems, where parts of those systems which are more quantifiable are more attentively managed, since more is known about them. Things which are difficult to convert to data may end up left on the wayside, since they cannot appear on a spreadsheet.
An example of this occurs with people who don’t have access to the internet. They are naturally omitted from any form of online polling and tracking, so their needs and interests will not be factored in to societal plans as easily as others.
This is similar to overfitting, in that the data which the societal model has access to may form patterns which do not give the full picture. The solution to this problem in machine learning can also have some benefit here. The solution to overfitting is ordinarily to keep some data separate, and use it to determine when the model is beginning to fall into irrationality. This can be done with datafication by not relying exclusively on big data for all of the answers. That said, data is cheap, and all of the other options cost more, so this is more of a hypothetical solution.